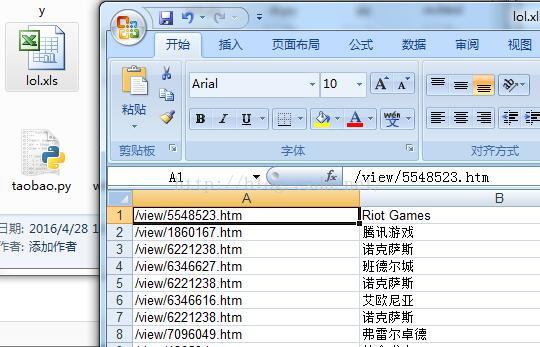
以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助. 相关阅读 : ## 百度百科:英雄联盟## 输出的部分截图如下: excel部分的截图如下:

元素对应博文内容,将这一段内容提取出即可. 为紧挨博文 的下一元素. 0x02 源码及注解 article_description中为博文摘要. article_manage中右下角的时间、阅读次数、评论次数 从article






#分析构造post数据 #给post数据编码 #构造请求 #解压缩 第三、运行结果
打开以后点击网络,网络用来记录浏览器和服务器交换的信息.接下来将鼠标滚轮缓慢向下滚动,在这个过程中就会弹出类似于上图的信息,也就是评论信息加载出来了.找到评论信息,应该会在第一条.如下图: 真实网址: 将网址在火狐里面打开如下图: 在这里就会涉
上面的网址其实pages=3就代表第三页,所以只需模拟网址即可,pages=4,5,6.... 另外由于是Json文件,所以提取数据非常方便,只需用切片操作即可. 长按扫描下方二维码, 获取本文源代码 编 程 狗 打开以后点击网络,


我选择的网站是中国天气网中的苏州天气,准备抓取最近7天的天气以及最高/最低气温 程序开头我们添加: 这样就能告诉解释器该py程序是utf-8编码的,源程序中可以有中文. 要引用的包: 最近两天学习了一下python,并自己写了一个网络爬虫的
Python爬虫,哪些奇特的网站值得一爬!谱时网爬虫实例 这个json数据中,存在了所有的页面加载的活动信息!没有翻页...怪不得加载那么慢呢[手动委屈]. Python爬虫,哪些奇特的网站值得一爬!谱时网爬虫实例 一个是活动相关信息,一个是图

我们可以看到,右侧出现了一大推代码,这些代码就叫做HTML.什么是HTML?举个容易理解的例子:我们的基因决定了我们的原始容貌,服务器返回的HTML决定了网站的原始容貌. 为啥说是原始容貌呢?因为人可以整容啊!扎心了,有木有?那网站也可以\"整容\"吗?可
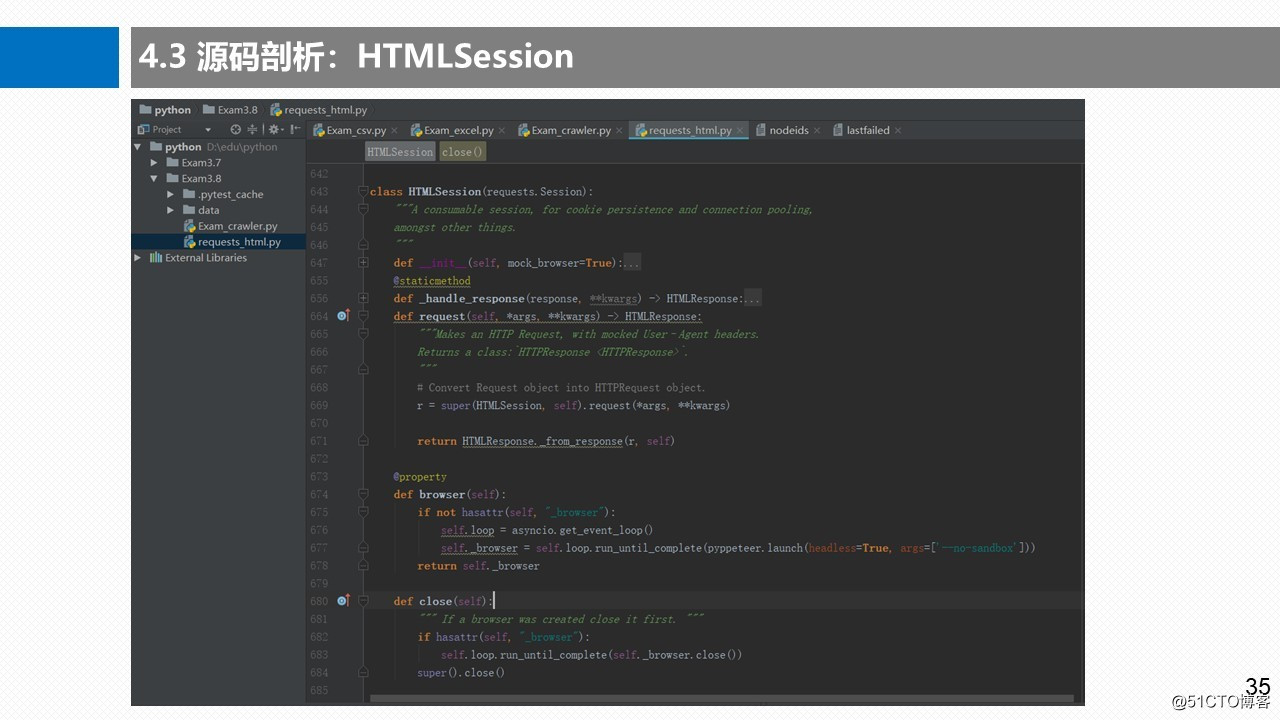
3.5 HTMLResponse请求响应类 3.6 HTML页面结构类 3.7 BaseParserHTML-基类 3.8 Element元素类 四、未完待续 《Python网络爬虫实战案例之:7000本电子书下载(1)》 3.5

由此可看,Python现在已然是站在了风口浪尖上,学习Python,还是非常有前景的! 下面有一些Python爬虫案例学习资料,需要的话可以自行下载学习! Python项目实战案例学习资料链接:https://pan.baidu.com/s/1_V

找到我们需要字段都在 id = \"7d\"的\"div\"的ul中.日期在每个li中h1 中,天气状况在每个li的第一个p标签内,最高温度和最低温度在每个li的span和i标签中. 代码如下: 这里我们主要要用到BeautifulSoup Beaut
Python爬虫,哪些奇特的网站值得一爬!谱时网爬虫实例 一个是活动相关信息,一个是图片相关信息,都是json格式加载的,这样就简单了,请求相关url就可以获取到,这时忽然想到,如果之前的多个活动页面也是动态加载的,那么是否可以通过这种方式将所有的活动

可以跟豆瓣首页进行对比. # 网址 print('失败') 爬取结果 (1)打印出来的信息 (2)爬取的图片列表

爬虫的价值将互联网上的数据为我所用,开发出属于自己的网站或APP 爬虫框架 爬虫调度端:用来启动、执行、停止爬虫,或者监视爬虫中的运行情况 成都达内是一家专业的Python培训机构,专注于成都Python培训,专业的成都Python培训班,专业
网友:张忆昨: “我保证不会说出去!”阿婉竖起手掌发誓,完了便催着白晏带路往牢狱深处走。
网友:宋氏亚:还是道,“不过冷姑娘也可多多搜集各种声音一道的法门,多多参悟,或许对冷姑娘你有帮助。
网友:黄法:你怎么样?逍遥快活的这些日子有没有吃好睡好玩好?都去玩什么了?有没有给我带礼物之类的,要不明天回家一趟吧,我让梅姨给你做一桌子的好菜,你这胃口只怕出门在外就没吃饱过吧?!”
网友:沈倩:因为自身宝物太少,南云圣体才第八层,所以根本无法修炼秘传两式!仅仅是九层实力,秘宝长枪虽然威力极大,却也只能发挥出九层巅峰威力罢了。
网友:史傅:在经脉的种种变化中,她比上一次更加容易的他身体的详细情况。
- 上一篇:创意展览 创意展览形式_有创意的展览主题
- 下一篇:返回列表




