excel部分的截图如下: 以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助. 您可能感兴趣的文章: python网络爬虫采集联想词示例 python使用rabbitmq实现网络爬虫示例 使用Python编写简单网络爬


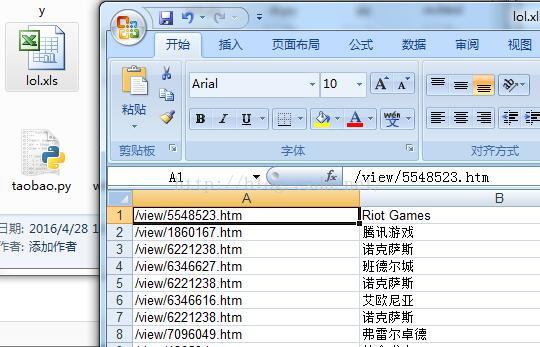
以上就是本文的全部内容,希望对大家学习Python网络爬虫有所帮助. 相关阅读 : ## 百度百科:英雄联盟## 输出的部分截图如下: excel部分的截图如下:

URL管理器在实现方式上,Python中主要采用内存(set)、和关系数据库(MySQL).对于小型程序,一般在内存中实现,Python内置的set()类型能够自动判断元素是否重复.对于大一点的程序,一般使用数据库来实现. 爬虫调度器调用网页下载器下载

我选择的网站是中国天气网中的苏州天气,准备抓取最近7天的天气以及最高/最低气温 程序开头我们添加: 这样就能告诉解释器该py程序是utf-8编码的,源程序中可以有中文. 要引用的包: 最近两天学习了一下python,并自己写了一个网络爬虫的

元素对应博文内容,将这一段内容提取出即可. 为紧挨博文 的下一元素. 0x02 源码及注解 article_description中为博文摘要. article_manage中右下角的时间、阅读次数、评论次数 从article

举一个 if 嵌套实例: 输入语句及结果如下: 6. 循环语句 5.3 常用操作运算符 5.4 if 嵌套 在嵌套 if 语句中,可以把 if...elif...else结构放在另外一个 if...elif...else 结构中.

找到我们需要字段都在 id = \"7d\"的\"div\"的ul中.日期在每个li中h1 中,天气状况在每个li的第一个p标签内,最高温度和最低温度在每个li的span和i标签中. 代码如下: 这里我们主要要用到BeautifulSoup Beaut


总结一下,从网页上抓取内容大致分3步: 1、模拟浏览器访问,获取html源代码 2、通过正则匹配,获取指定标签中的内容 3、将获取到的内容写到文件中 然后运行一下: 生成的weather.csv文件如下:



timeout是设定的一个超时时间,取随机数是因为防止被网站认定为网络爬虫. 然后通过requests.get方法获取网页的源代码、 rep.encoding = 'utf-8'是将源代码的编码格式改为utf-8(不该源代码中中文部分会为乱码)


上面的网址其实pages=3就代表第三页,所以只需模拟网址即可,pages=4,5,6.... 另外由于是Json文件,所以提取数据非常方便,只需用切片操作即可. 长按扫描下方二维码, 获取本文源代码 编 程 狗 打开以后点击网络,

真实网址: 将网址在火狐里面打开如下图: 上面的网址其实pages=3就代表第三页,所以只需模拟网址即可,pages=4,5,6.... 另外由于是Json文件,所以提取数据非常方便,只需用切片操作即可. 长按扫描下方二维码, 找到真实

#分析构造post数据 #给post数据编码 #构造请求 #解压缩 第三、运行结果
网友:郝虹芸:拼着受伤也要一举解决东伯雪鹰。
网友:黄奉肝:即便苏河拼尽全力,将所有帮手都叫出来,恐怕也不是对手。
网友:熊衍乐:“针对?”毒郢界神冷笑,“他也配?”
网友:周佃穷:他的实力要赢凶巫战兵,恐怕有些难度。
网友:黄闾: 苏河嘴角露出一丝邪恶的笑意,又一道紫雷落下,直奔那只混沌之兽的屁股而去!
- 上一篇:国外ip 国外免费ip_snapchat安卓下载
- 下一篇:返回列表